

前回で、指定ページの情報を収集できるようになったのう。
「リンク先情報を取得するget_attribute()」を忘れんようにじゃな。
(ドエスタ)
なんかWebスクレイピングできそうな気がしてきました。でもね、ペンぞうさん。データ収集のお仕事で多いのは、「URLリストをCSV(もしくはスプレッドシート)があるので、そのURLから必要なデータを収集してください」ってケースが多いみたい。
その通りじゃ。同一サイト内のアイテムの状況確認などもよくあるのう。自動テスト(3)で
URLの読み込みには触れたし、今回はファイル読み込みも含めて実践してみるぞい。
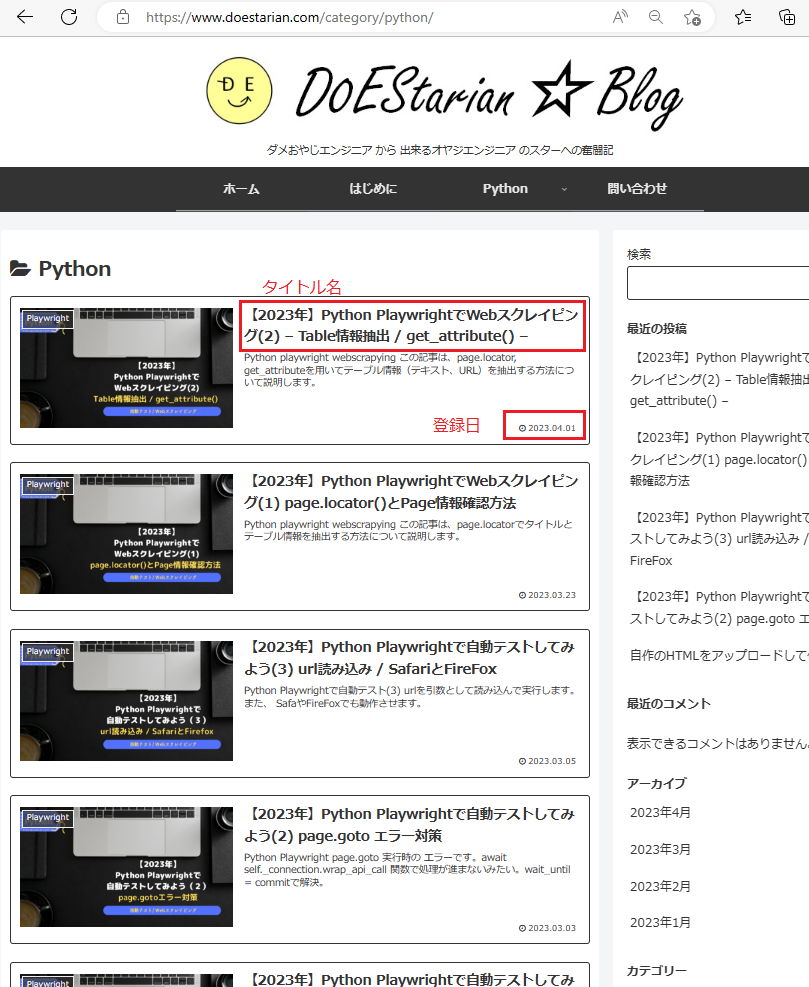
問題① url1.csvのデータ収集
url1.csvに記載されているURLを読み込み、
URL先の各投稿の「タイトル名(Title)」、「登録日(Entry_date)」のデータを収集してください。
収集結果ファイルは、カテゴリ名.csvで出力して下さい。
(例) Category=pythonの場合は、python.csv
【入力ファイル】url1.csv
| No | Category | URL |
| 1 | python | https://www.doestarian.com/category/python/ |
| 2 | wordpress | https://www.doestarian.com/category/wordpress/ |
【出力結果例】python.csv , wordpress.csv 下記は2023.4.24現在の結果です。投稿記事の増減により出力結果が異なります
| Title | Entry_date |
| 【2023年】Python PlaywrightでWebスクレイピング(2) – Table情報抽出 / get_attribute() – | 2023.04.01 |
| 【2023年】Python PlaywrightでWebスクレイピング(1) page.locator()とPage情報確認方法 | 2023.03.23 |
| 【2023年】Python Playwrightで自動テストしてみよう(3) url読み込み / SafariとFireFox | 2023.03.05 |
| 【2023年】Python Playwrightで自動テストしてみよう(2) page.goto エラー対策 | 2023.03.03 |
| 【2023年】Python Playwrightで自動テストしてみよう | 2023.02.06 |
| Title | Entry_date |
| 自作のHTMLをアップロードして使おう | 2023.02.25 |
| Canvaでアイキャッチ画像を作ろう | 2023.02.11 |
| WordPressで吹き出しを作成しよう | 2023.02.11 |
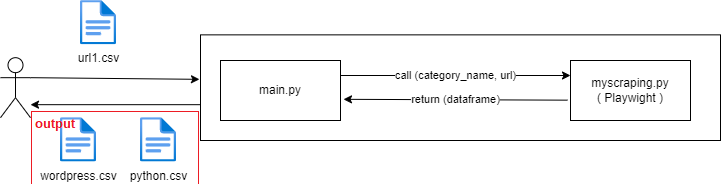
解答例
今回は、main関数をURLリスト読み込み、結果出力を行うだけの簡単な処理に、そして、myscraping.pyをplaywrightによるデータ収集専用の処理にわけました。
出力結果は、outputフォルダーに出力しました。
#====================================================
# main.py
# (url1.csvのデータ収集)
#
# V1.0 2023.4.23 : 初版
#====================================================
import pandas as pd
import time
import myscraping
start = time.time()
# csv 読み込み
df_csv = pd.read_csv("url1.csv",index_col=0)
# scrapying report 生成
print(f'No,Result,Category,URL')
for i in range(len(df_csv)):
category = df_csv.iloc[i]['Category']
url = df_csv.iloc[i]['URL']
# スクレイピング実行
result, result_df = myscraping.scrape(url)
print(f'{i},{result}, {category}, {url}')
# 結果出力
result_csv_name = "output/"+category+".csv"
result_df.to_csv(result_csv_name, index=False)
end = time.time()
elapsed_time = end - start
print(f'経過時間:{elapsed_time:.2f} 秒')from playwright.sync_api import Playwright, sync_playwright, expect
import pandas as pd
def playwright_run(playwright: Playwright, url, df):
browser = playwright.chromium.launch(headless=True)
context = browser.new_context()
#### 1.Open url page
page = context.new_page()
page.goto(url)
#### 2.情報取得
# Title取得
titles = page.locator('h2.entry-card-title.card-title.e-card-title').all_inner_texts()
# print(titles)
# 登録日取得
entry_dates = page.locator('span.entry-date').all_inner_texts()
# print(entry_dates)
# Close page
page.close()
context.close()
browser.close()
#### 3.収集結果データ作成
new_df = pd.DataFrame({'Title': titles,'Entry_date': entry_dates})
df = pd.concat([df, new_df], ignore_index=True)
# print(df)
return "OK", df
def scrape(url):
result = "OK"
# 結果出力の空フレーム作成
cols = ['Title','Entry_date']
df = pd.DataFrame(columns=cols)
# Playwright 実行
with sync_playwright() as playwright:
result,df = playwright_run(playwright,url,df)
return result, df■ポイント
pate.locator().all_inner_texts() を使って「タイトル名」、「登録日」を一括取得しました。
titles = page.locator('h2.entry-card-title.card-title.e-card-title').all_inner_texts()
entry_dates = page.locator('span.entry-date').all_inner_texts()その後、結果出力用のDataframeを作成しています。
new_df = pd.DataFrame({'Title': titles,'Entry_date': entry_dates})実行結果
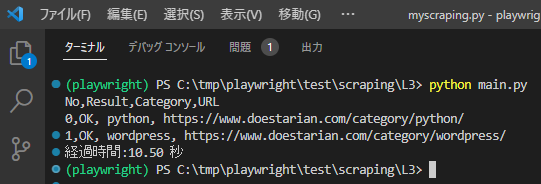
こちらは、処理の様子の動画で撮影したものです。
さいごに
今回は、pate.locator().all_inner_texts()で、「タイトル名」、「登録日」を一括取得してみました。また、URLリスト読み込み、結果ファイル出力するだけでなく処理時間も計測してみました。
SeleniumやScrapyを試したときもそうでしたが、Webスクレイピングフレームワークは処理はそんな速くないと改めて感じました。ただ、非同期処理の適用や、リスト処理の見直しなどでさらに処理時間の短縮を図りたいとおもいます。
Playwrightに関しては、処理改善だけでなく、まだまだ紹介したいことがたくさんあります。
- エラー対応
- エラー画面のSnapshot取得
- タイムアウト回避
- ダウンロードボタン押下によるファイルダウンロード
- 階層的URL対応
スクレイピングした結果から得られたURLにジャンプして必要なデータを収集する
ご期待ください。
コメント